- kafka, Pulsar, Kinesis: 이벤트 streaming을 위한 streaming platform
- streaming이 중요한 이유
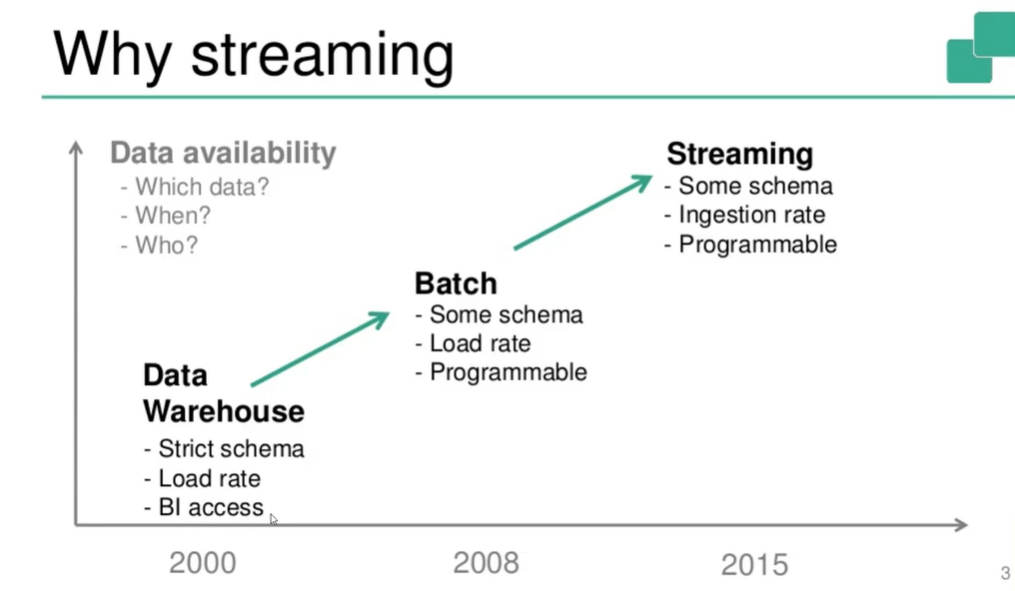
- Data availability 때문임
- 어떤 데이터를, 누가, 언제 접근할 수 있게 해주는가?
- Data Warehouse(2000년대, 클라우드 이전)
- 용량에 제한이 있었음 -> Production DB에서 분석을 위한 데이터만 뽑아서 Transform했음 -> 엄격한 Schema에만 집어넣어야 했음
- ETL(transform) 이후 load할 때 BI 도구를 통해 access할 수 있었음 -> 실시간 접근이 불가능 -> 속도 느림
- Batch(Hadoop을 이용하던 시기)
- 예전보다는 여러 schema를 지원
- BI 도구 이외에도 다른 도구를 위해 접근은 가능(Programmable), but 여전히 ETL 이후에만 데이터 접근 가능
- Streaming(현재)
- Ingestion 시점부터 접근 가능 (실시간)
- spark도 streaming을 지원하긴 하지만 기본적으로 batch 기반
- micro-batch라는 500ms마다 번갈아가며 일을 처리하는 시스템 때문에 실시간처럼 보이는 것임
- True Streaming은 데이터가 들어올 때마다 처리가 가능함 (오늘 이야기할 플랫폼들이 여기에 해당)
- Apache Kafka
- linkedin에서 처음 만들어졌으며, 오픈소스 분산 이벤트 스트리밍 플랫폼임
- 데이터가 많은 회사들에서 표준처럼 쓰이는 플랫폼
- fault tolerant함 : 랙이 내려가도 손실 없이 복구할 수 있음
- Kafka의 architecture
- source application: 웹/ 앱 등 이벤트가 일어나는 application
- target application: RDBMS, key-value store 등 event를 저장하는 application
- 처음에는 source와 target이 한 개씩만 있다가 점점 source/target모두 개수가 많아짐
- 데이터를 전송하는 라인이 많아지고, 이러면 배포와 장애에 대응하기 어려움
- 데이터 전송 라인을 효과적으로 정리하기 위해 생겨난 것이 Kafka임
- 기본적으로 source application과 target application의 link를 약하게 만듦
- kafka를 이용하면 source application은 apache kafka에 데이터를 전송하고, target application은 apache kafka에서 데이터를 가져오면 됨
- source application에서 보낼 수 있는 데이터 유형은 거의 제한이 없음(Json, Tsv, AVrO 등)
- Kafka에는 데이터를 담을 수 있는 'topic'이라는 개념이 있음(=queue)
- queue에 데이터를 넣을 수 있는 일은 producer라고 하고, queue에서 데이터를 가져가는 일은 consumer가 함
- producer와 consumer는 library여서 application에서 구현 가능함
'Data science > ML' 카테고리의 다른 글
| 긱뉴스 - 최신 데이터 인프라 이해하기 #5 Spark, Python, Hive (0) | 2022.04.14 |
|---|---|
| 긱뉴스 - 최신 데이터 인프라 이해하기 #4 데이터 모델링과 워크플로우 매니저 (0) | 2022.04.13 |
| 긱뉴스 - 최신 데이터 인프라 이해하기 #3 ETL/ELT 도구들 (0) | 2022.04.13 |
| 긱뉴스 - 최신 데이터 인프라 이해하기 #2 데이터 소스 (0) | 2022.04.13 |
| 긱뉴스 - 최신 데이터 인프라 이해하기 #1 기본 개념과 단어 설명 (0) | 2022.04.13 |
